CSV to JSON using Google Data Flow pipeline
Today in this article we will see how to get started with Google data flow and Apache beam services and create a simplified streaming data pipeline.
Today in this article, we will cover below aspects,
We shall learn how to create a data flow job that will read a CSV file from a google storage bucket and then convert it to JSON format.
Prerequisites
Setup the prerequisites and environment,
- Create a Google Cloud project. Make sure that billing is enabled for this project.
- Enable all the Google APIs required for the projects.

- Make sure to create a Google Cloud storage for storing the data.
- Set up the Environment
- Install Apache Beam – Install Apache beam using the Google cloud console
- If running the application locally using IDE -Please install the package the same way Example- console CLI in VS Code
pip install 'apache-beam[gcp]'
- Set up the Service account google project and add the required permission/role required as per the need.
Getting started
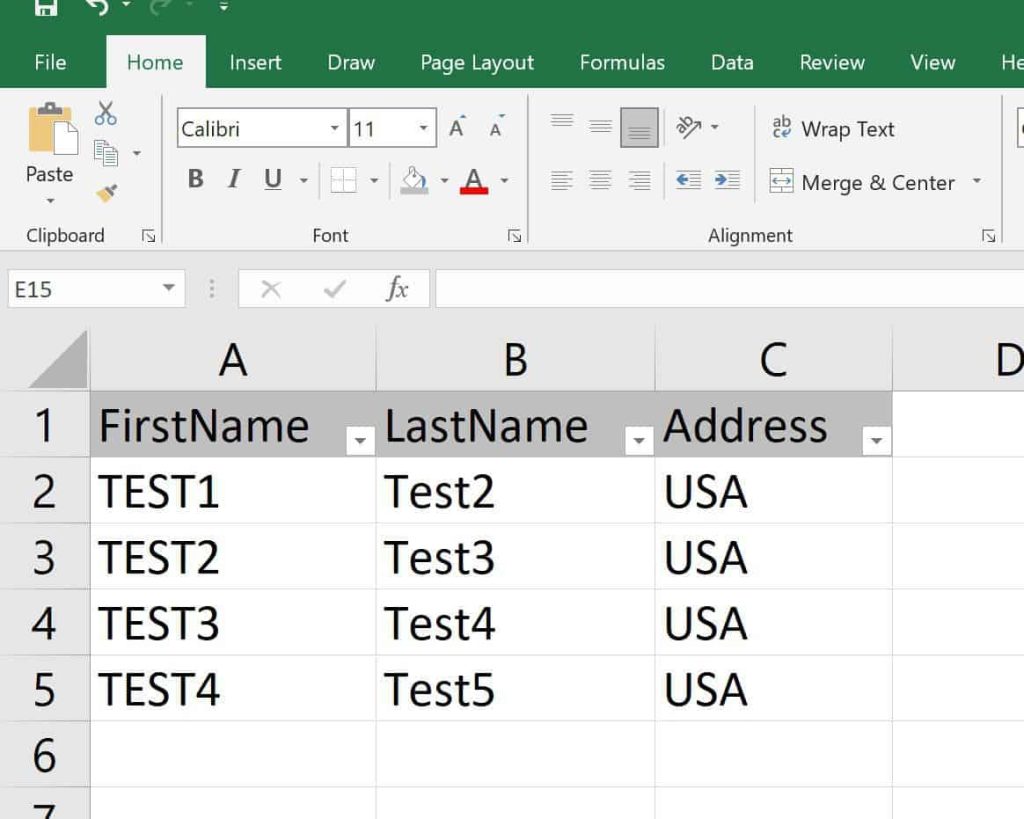
Let’s upload the sample CSV file to the google GCP bucket.
I have a sample file as shown below which we shall upload to the GCP environment.
Below I have created the “Input” folder within the Bucket where the file is located.

Please click on the file and copy its location as highlighted.
All the files located in the bucket will be denoted as common folder naming as below example,
gs://test-bucket-13/Input/Adress.csv
Configure the Dataflow Job
Configuring the Dataflow Job can be done using the GCP console or using the UI Dataflow interface.
You can get started with Google-provided templates for a basic understanding of the workflow. OR you can use your own custom templates.
In any of the above cases, you need to configure the various properties which are discussed below.
Please configure the Data flow job for the properties example -JobName, Region, Input file location, output file location, template location, etc
The output shall be generated in the below output folder.
test-bucket-13/output
Setting up security credentials – GOOGLE_APPLICATION_CREDENTIALS
If you have created a dedicated dataflow service account then this account can be configured to use in the Dataflow pipeline using Python code as below,
import os os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = 'secured.json'
Above enviornment variable can be set using automated technqiues like deployment pipeline etc.
Note :
You can download your secured.json from the Service account page,
Convert CSV to JSON using Python
Below is the logic using the pandas library, which converts CSV files to JSON files.
class CsvToJsonConvertion(beam.DoFn):
def __init__(self, inputFilePath,outputFilePath):
self.inputFilePath = inputFilePath
self.outputFilePath = outputFilePath
def start_bundle(self):
self.client = storage.Client()
def process(self, something):
df = pd.read_csv (self.inputFilePath)
df.to_json (self.outputFilePath)
Below is the command line argument setup,
class DataflowPipeline(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser):
parser.add_argument('--inputFilePath', type=str, default='gs://test-bucket-13/Input/Address.csv')
parser.add_argument('--outputFilePath', type=str, default='gs://test-bucket-13/output/temp/Address.json')
The user will be able to provide the input file path and output file location. If not specified above default argument will be used.
Below is the parser and pipeline execution complete code flow,
class DataflowPipeline(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser):
parser.add_argument('--inputFilePath', type=str, default='gs://test-bucket-13/Input/Adress.csv')
parser.add_argument('--outputFilePath', type=str, default='gs://test-bucket-13/output/temp/addressfrom-gcp1.json')
class ConvertCSVToJson(beam.DoFn):
def __init__(self, inputFilePath,outputFilePath):
self.inputFilePath = inputFilePath
self.outputFilePath = outputFilePath
def start_bundle(self):
self.client = storage.Client()
def process(self, something):
df = pd.read_csv (self.inputFilePath)
df.to_json (self.outputFilePath)
def run(argv=None):
parser = argparse.ArgumentParser()
known_args, pipeline_args = parser.parse_known_args(argv)
pipeline_options = PipelineOptions(pipeline_args)
dataflow_options = pipeline_options.view_as(DataflowPipeline)
with beam.Pipeline(options=pipeline_options) as pipeline:
(pipeline
| 'Start' >> beam.Create([None])
| 'Convert CSV to JSON' >> beam.ParDo(ConvertCSVToJson(dataflow_options.inputFilePath, dataflow_options.outputFilePath))
)
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
Let’s run the data flow job on the GCP console,
Setup Project Dependencies using requirements.txt or setup.py
To Setup Project Dependencies use either requirements.txt or use setup.py
requirements.txt
Below is the sample requirements.txt file,
google-cloud-storage==1.28.1 pandas==1.2.2 gcsfs==0.7.1
Alternatively, please use setup.py
You use setup.py to specify all dependencies your application needs.
setup.py
import setuptools
REQUIRED_PACKAGES = [
'google-cloud-storage==1.35.0',
'pandas==1.2.2',
'gcsfs==0.7.1'
]
PACKAGE_NAME = 'TheCodebuzzDataflow'
PACKAGE_VERSION = '0.0.1'
setuptools.setup(
name=PACKAGE_NAME,
version=PACKAGE_VERSION,
description='Set up file for the required Dataflow packages ',
install_requires=REQUIRED_PACKAGES,
packages=setuptools.find_packages(),
)
Specifying setup.py for the Dataflow task
Specifying setup.py can be achieved by any of the below approaches discussed.
A] Using SetupOptions
Please use the SetupOptions to set the setup file as shown below,
pipeline_options = PipelineOptions(pipeline_args)
setup_options= pipeline_options.view_as(SetupOptions)
dataflow_options = pipeline_options.view_as(DataflowPipeline)
setup_options.setup_file = "./setup.py"
B] Using the command specifying setup.py
Please append your dataflow commands with –setup_file argument as below.
--setup_file ./setup.py
Running Dataflow command
The dataflow command can be run directly by specifying all the options within the command line or can be run as a template from the Google Dataflow web interface.
Dataflow command
python3 dataflow.py --project test1-303520 --runner DataflowRunner --staging_location gs://test-bucket-13/ --temp_location gs://test-bucket-13/temp --save_main_session True --requirements_file requirements.txt --input gs://test-bucket-13/Input/Adress.csv --output gs://test-bucket-13/output/temp/Address.json --region us-central1 --job_name dataflowcsvjson
Running Dataflow command using a template
We can create a reusable Dataflow template from the below command,
python3 dataflow.py --project test1-303520 --runner DataflowRunner --staging_location gs://test-bucket-13/ --temp_location gs://test-bucket-13/ --template_location gs://test-bucket-13/template/csvjsontemplate --region us-central1 --job_name dataflowcsvjson Above commands will create a template and put it into GCS as below location,
Now create a Dataflow job from generated templates as below,
Once you run the above template, the job will run and produce the result as above.
Generated JSON file will be available in google bucket,
Note: Please make sure your Dataflow Service account has all permission/roles as per the guidelines.
That’s All!
References
Do you have any comments or ideas or any better suggestions to share?
Please sound off your comments below.
Happy Coding !!
Please bookmark this page and share it with your friends. Please Subscribe to the blog to receive notifications on freshly published (2025) best practices and guidelines for software design and development.
NameError: name ‘pipeline_args’ is not defined on running the above code
Hi Vamsi- Please check if you have initialized all inputs. Did you define this argument as pipeline_args = parser.parse_known_args(argv) ?
When I try to run this code I get this error raise TypeError(‘Expected a callable object instead of: %r’ % fn)
TypeError: Expected a callable object instead of: ‘gs://usis-d360-syntheticid-data-npe/csv-to-json-test/zip-codes-database-DELUXE-csv_nov21.csv’
Do you know how I would fix this?
Hi Skelly, Thanks for your query. Hope you have defined init and DoFn correctly. Also, refer to apache beam documentation for any new updates.
please refer this link this